|
|
|
|
|

|
This section deals with secure voice cipher equipment (voice crypto)
from a variety of manufacturers. Voice encryption devices come in many
flavours, ranging from small military radio
add-ons to desktop telephone encryptors. Most of the units shown here,
are also available in other categories on this website.
Secure telephones are a class of their own,
but since they also belong to the group of voice encryption devices,
they are linked from this page
as well.
Voice crypto units on this website:
|
|
|
|
|
|
|
|
|
|
Most - if not all - modern secure voice terminals use digital encryption.
Speech is digitized by means of an Analog-to-Digital Convertor (ADC) or
a Vocoder. The resulting digital data stream is then 'mixed' by means of
an XOR-operation with a data stream from a pseudo-random number
generator, that in turn is seeded by a KEY.
This results in an encrypted data stream that is then converted back to the
analog domain (modem), so that it can be transmitted.
This process is shown in the simplified diagram below:
During the 1970s many systems, such as the KY-57
used Continuous Variable Slope Delta modulation (CVSD) to convert speech into digital data. This wide-band solution was only suitable for VHF and UHF radios.
In the 1980s narrow-band systems were introduced,
such as the KY-99 that used (enhanced) Linear Predictive
Coding (LPC), limiting the data-rate to 2400 baud or even 800 baud.
The Pseudo Random Number Generator (PRNG) is seeded by a KEY that is either
entered manuall or by means of a key fill device. Modern systems sometimes
use asymmetric encryption methods (e.g. AES) to exchange the keys over an
insecure channel (public key encryption).
|
Below are some sound samples of digital voice encryption.
They were recorded by Barry Wels [1] on an Icom IC-H10SR.
The first file contains the original audio file. The seconds file plays
the encryption audio. Finally, the last file produces the audio once it
has been decrypted.
|
Before digital speech encryption became widely available, another technique
was used to secure voice transmission. This technique was based on frequency
inversion and is commonly called voice scrambling.
It evolves around mirroring of the audio frequency spectrum around a given
center frequency, sometimes divided over multiple frequency bands.
This principle is best explained using a simplified model:
The audio spectrum of the voice data is mixed with a carrier frquency
(fc). This results in two spectra: one that is the sum
of the original sectrum and the carrier, and one that is the difference of
the two signals. A low-pass filter (LPF) is then applied to filter off the
sum and leave only the difference, effectively resulting in a mirrored
audio band. At the receiving end, the audio spectrum is mirrored once more
to make it 'legible' again.
To make things more complex, one could vary the carrier frequency and also
split-up the audio band in several (e.g. five) smaller bands that are then
mirrored individually. Continuously varying these parameters by putting them
under digital control, can make it harder to decode the signal.
The advantage of this technique is that it completely takes place within the
audio bandwidth of a channel, whereas digital encryption generally requires
a (much) larger bandwidth. This allows voice scrambling to be added to an
existing analog radio system. For this reason, the police in many countries
used scramblers from the 1970's well into the 1990's.
The disadvantage however is that an evesdropper can easily reverse the process
of frequency mirroring with a simple piece of electronics.
Furthermore it is sometimes even possible to extract usefull information from
the seemingly garbled speech by listening carefully.
Even complex digitally-controlled voice scramblers are easily defeated by
today's software defined radio solutions, that have become widely available.
Voice scrambling is therefore considered inherently insecure.
|
|
|
Time-division speech scrambler
|
 |
|
|
A third method for secure speech is the so-called time-division speech
scrambling. This method is more secure than the simpler
frequency-inversion system, but far less secure than modern
digital speech encryptors.
It was introduced in the mid-1970s and served well into the 1990s.
Many police and other law enforcement agencies world-wide, used this system
for securing their conversations.
The advantage of this system is that it is suitable for narrow-band FM
channels, as the output signal consists purely of voice information.
The system is prone to cryptographic attacks however, as it is possible to
reconstruct the original signal (and hence the cryptographic key) by examining
the output signal on an oscilloscope.
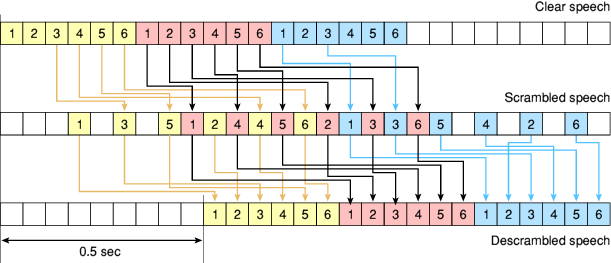
The simplified diagram below, shows how it works.
Speech is cut into small time segments and is scrambled with other time segments
in an ever changing order. The order in which the packets are scrambled is
determined by a pseudo random number generated that is seeded by the user.
In this diagram, the top row shows the clear speech (input) in time.
The second row shows the speech after it is scrambled.
Finally, the bottom row shows the speech once it is descrambled again (output).
The whole process of scrambling and descrambling, causes a typical delay of
approx. 0.5 seconds.
As the time segments are scrambled in an ever changing pattern, it is important
that transmitter and receiver are correctly synchronised. To ensure that both
ends are kept 'in sync', a pilot signal (FSK) is transmitted with the
scrambled speech.
An example of a time-division speech scrambler is the
BBC Cryptophon 1100.
|
The examples below were recorded by Barry Wels [1] from the built-in analogue
voice scrambler of the Icom IC-H11 radio. If you listen carefully to the
scrambled audio, you may actually be able to descramble it yourself.
|
|
|
|
Any links shown in red are currently unavailable.
If you like this website, why not make a donation?
© Copyright 2009-2013, Paul Reuvers & Marc Simons. Last changed: Tuesday, 01 April 2014 - 10:29 CET
|
|

|
|












")

















")


")